
For Sale: A 12 GB GPU That Runs Local LLMs at ~60 tok/s
GIGABYTE RTX 3060 EAGLE OC 12 GB — $350 shipped anywhere in CONUS.
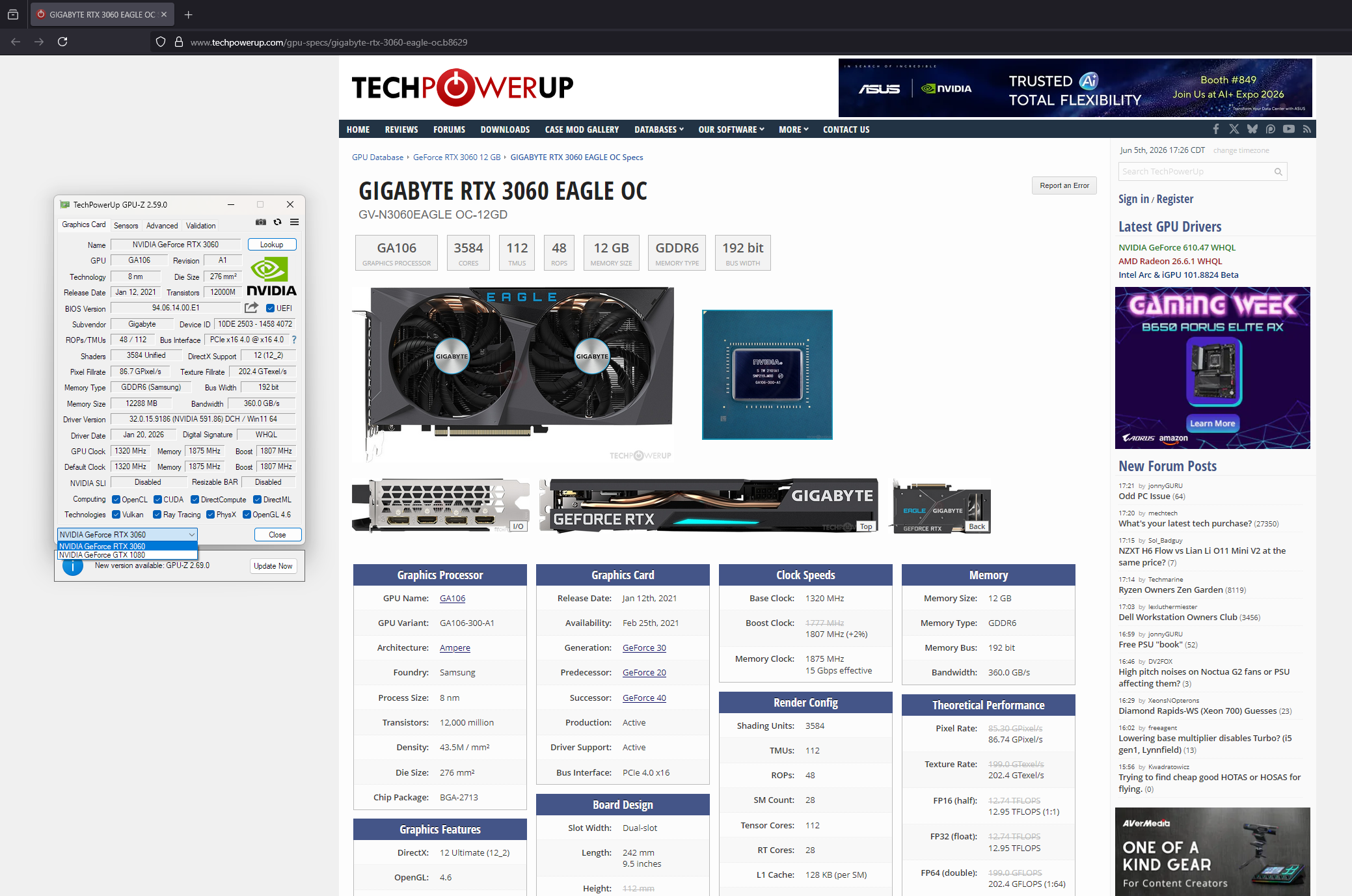
Specs via TechPowerUp’s GPU database.
I’m selling a graphics card. The quick pitch: it’s a GIGABYTE RTX 3060 EAGLE OC with 12 GB of VRAM — and that VRAM is the whole story for local AI.
Twelve gigs is the sweet spot for running modern small models entirely on your own hardware — no API keys, no per-token billing, nothing leaving the box:
- 8B-class LLMs at ~60 tok/s. Qwen3-8B fits comfortably and generates at around 60 tokens/second — fast enough to feel interactive.
- Runs Google’s new Gemma 4 with function calling, so you can wire it into tool-using agents locally.
- All in vLLM — batched, production-grade serving on a single card.
For a homelab inference box, a quiet always-on coding assistant, or just learning how local models actually behave, 12 GB of VRAM at this price is hard to beat.
Specs at a glance
| GPU | NVIDIA GeForce RTX 3060 (GA106) |
| Memory | 12 GB GDDR6 |
| Card | GIGABYTE EAGLE OC, dual-fan |
| Price | $350 shipped — CONUS only |
Interested? Reply to the original post on Mastodon and we’ll sort out the details.
Written on June 5, 2026